Directives et exigences pour chercher dans les index de WorldCat
Survol
Lors du survol, l'index est balayé afin de trouver un terme correspondant au terme de recherche, ou le terme le plus proche, et de récupérer les notices appropriées. Lorsque vous sélectionnez un terme dans les résultats de recherche, les notices pertinentes sont récupérées.
Dans la description de chaque index, il est indiqué si l'index permet la recherche uniquement, ou la recherche et le survol.
Vous pouvez survoler les index de WorldCat de deux façons :
- En utilisant un mot qui apparaît dans n'importe quelle zone et sous-zone indexées.
- En utilisant une expression exacte (sous-zone complète) ou une expression complète (zone complète) : cette expression doit commencer par le premier mot de la phrase et inclure tous les mots (sauf le ou les articles au début du titre). Pour l'expression que vous inscrivez, la correspondance est établie caractère par caractère, de gauche à droite, avec la phrase dans l'index que vous avez indiqué.
Le système retourne une liste de termes contenant le terme correspondant, ou le terme le plus près, et les termes qui précèdent et suivent le terme correspondant. Lorsque vous sélectionnez un terme dans la liste, la notice ou la liste de notices récupérées pour ce terme est affichée.
Majuscules
Vous pouvez inscrire les libellés d'index et les termes de recherche en lettres minuscules, majuscules ou les deux.
Index par défaut
Si vous n'indiquez pas de libellé d'index, le système utilise l'index Mot-clé (kw:) par défaut.
Recherche dérivée
La recherche dérivée réduit le nombre de touches que vous devez entrer.
La recherche dérivée utilise un nombre précis de caractères initiaux dans les mots séquentiels d'un nom ou d'un titre.
- Les segments « dérivés » des mots sont séparés par des virgules.
- Un mot est défini comme lors d'une recherche mot-clé (caractère(s) entre deux espaces vides).
- Le nombre, et le modèle de lettres et de virgules, indiquent au système dans quel index dérivé chercher.
- Lors d'une recherche par commandes dans Connexion, ou d'une recherche experte dans FirstSearch, l'utilisation d'un libellé d'index dérivé et de la ponctuation est facultative s'il s'agit du premier élément, ou du seul élément, de la recherche. Utilisez toujours des libellés d'index et la ponctuation lorsque vous combinez une recherche dérivée avec une recherche dans un index différent.
Articles initiaux (« Le », « The », « Des », etc.)
URL Internet et zone 856
Lors d'une recherche d'URL Internet en lien avec la zone 856, utilisez mt:url pour savoir si la zone 856 existe dans une ressource Internet uniquement. Il est également possible de chercher mt:web pour récupérer les notices contenant n'importe quel type de zone 856. De plus, consultez Méthode d'accès pour des informations sur la recherche de URL et la zone 856.
Niveaux de recherches
Pour plus de flexibilité pour les stratégies de recherche et plus de contrôle sur les résultats, OCLC offre divers niveaux de recherche, allant des recherches simplifiées ou aux recherches complexes.
Les exemples de recherches fournis dans ce guide sont des recherches formulées par commandes (expertes). À partir de ces exemples, vous pouvez remplacer des parties de la recherche, et entrer ou sélectionner des index et des opérateurs dans les boîtes pour formuler votre énoncé de recherche plus simplement.
Jeux de caractères non latins
L'interface client de Connexion et l'interface de FirstSearch prennent en charge tous les caractères UTF-8 Unicode définis pour les termes de recherche en caractères non latins, ce qui comprend les jeux de caractères MARC-8 non latins suivants : arabe, chinois, cyrillique, grec, hébreu, japonais, coréen, ainsi que tous les jeux de caractères UTF-8 Unicode. Pour la liste complète des jeux de caractères acceptés, voir Unicode character code charts.
Arabe standard moderne
WorldCat Discovery vous permet de chercher et de trier en utilisant l'arabe standard moderne.
Diacritiques
WorldCat Discovery renvoie les mêmes résultats, que les utilisateurs saisissent des termes de recherche avec ou sans signes diacritiques, comme la hamza « ء» ou la madda « آ». Par exemple, nous considérons les éléments suivants comme équivalents :
- “ى” et ”ي”,
- “ه” et ” ة ”
- “آ” “ا” “إ” “أ”
Articles définis et préfixes
Pour les recherches de titres, les résultats sont les mêmes avec ou sans article défini ou préfixe. Par exemple :
- Les articles définis sont supprimés : "ال"
- Les préfixes sont ignorés : "ب" "ك" "ف" "لل"
Kashida
WorldCat Discovery traite les caractères de la même manière, qu'ils soient allongés ou non. Par exemple :
- Avec kashida : “مـديـنــــــــــــــــة “
- Sans kashida : “مدينة”
Thaï standard
WorldCat Discovery vous permet de chercher et de trier en utilisant le thaï standard.
Normalisation
La normalisation n'est appliquée à aucun index en thaï. Tous les symboles de voyelles et signes diacritiques thaïs sont considérés comme significatifs et ne sont jamais ignorés.
- Exception - Caractères avec marques de ton : composés/décomposés
Les caractères thaïs qui ont des marques de ton dans les formes composées et décomposées sont indexés.
Exemple :
Lorsqu'il est saisi sous forme composée dans un terme de recherche, le caractère correspondra à la fois à la forme composée et à la forme décomposée dans l'index et vice versa : si la recherche est effectuée sous forme décomposée, elle correspondra à la fois à la forme décomposée et à la forme composée.
Segmentation en unités lexicales
Étant donné que les phrases en écriture thaïe sont écrites sans espace entre les mots, pour reconnaître et indexer les mots thaïs individuels, la segmentation est appliquée pour construire tous les index de mots thaïs et pour analyser les requêtes d'index de mots. La segmentation ,n'est pas appliquée pour les index 'expression' ou les requêtes d'index 'expression'.
L'indexation des mots thaïs individuels permet une recherche par index de mots qui permet de récupérer les notices contenant les termes de la requête n'importe où dans les zones indexées appropriées.
|
|
Thaï |
Traduction en anglais |
|---|---|---|
|
Requête |
ti:สนทนาภาษาจีน |
Chinese conversation |
|
Requête avec segmentation |
· สนทนา · ภาษา · จีน
|
· talk/converse · language · China |
|
Titre de la notice correspondante |
สนทนา 3 ภาษา ไทย-อังกฤษ-จีน โต้ตอบอย่างมั่นใจ พิชิตงานบริการในโรงแรม |
Conversation in three languages: Thai-English-Chinese. Respond confidently and conquer service jobs in hotels. |
|
Titre de la notice avec segmentation |
สนทนา 3 ภาษา ไทย อังกฤษ จีน โต้ตอบ อย่าง มั่นใจ พิชิต งาน บริการ บริการ_ใน ใน ใน_โรงแรม โรงแรม |
Talk/Converse 3 language Thai England China respond at/manner confident conquer work service service_in in in_hotel hotel |
Mots courants
Si l'on se réfère à la liste des mots thaïs standards courants ci-dessous, plutôt que de les traiter comme des mots vides, ce qui reviendrait à les ignorer pour l'indexation et la mise en correspondance, nous les combinons avec les mots adjacents lorsque nous construisons des index de mots et analysons les requêtes d'index de mots.
Lorsqu'un mot thaï courant est ignoré (traité comme un mot vide), le mot adjacent qui reste peut avoir un sens différent de celui qu'il aurait s'il était combiné/adjacent à un mot courant. Cette différence de sens peut conduire à la récupération de notices non pertinentes. Dans les cas où le sens d'un mot aurait changé si nous avions supprimé le mot courant adjacent, le fait de le combiner avec le mot courant adjacent permet de désambiguïser son sens, ce qui améliore la précision de la recherche en réduisant la récupération de notices non pertinentes.
Nous appliquons le traitement des mots courants décrit ci-dessus lors de la création et de la recherche dans les index suivants :
- se: Series (Collection)
- ti: Title (Titre)
- kw: Keyword (Mot-clé)
Mot courant traité comme un mot vide
- Requête ti:มาตราการ (mesures/procédure)
- Segmenté en มาตรา et การ
- Le mot courant การ est supprimé comme mot vide laissant seulement มาตรา.
- มาตรา a une signification différente (article ou clause de loi) de มาตราการ (mesures/procédure) et renvoie donc à des notices qui ne sont pas pertinentes pour la requête ti:มาตราการ
Mot courant traité comme un mot adjacent
- Requête ti:มาตราการ (mesures/procédure)
- Segmenté en มาตรา_การ (parce que การ est défini comme un mot courant)
- Notices avec zones de titre contenant มาตราการ
- Titres segmentés en มาตรา มาตรา_การ การ
- Uniquement les notices contenant มาตราการ sont récupérées.
Liste de mots courants en thaï :
|
กว่า กับ การ ก็ ขณะ ของ ความ คือ จะ จึง |
ซึ่ง ด้วย ตั้งแต่ ต่างๆ ถึง ถ้า ทั้ง ทั้งนี้ ที่ นั้น |
นี้ ว่า หรือ หาก อะไร อาจ อีก เช่น เนื่องจาก เป็นการ |
เพื่อ เมื่อ เลย เอง แต่ และ แล้ว โดย ใน ไว้ |
Tri
Nous trions les zones d'auteur, de titre et de cote en thaï standard en utilisant l'ordre de classement par défaut de l'algorithme de classement Unicode que nous appliquons à tous les jeux de caractères et à toutes les langues.
Le tri alphabétique est disponible dans WorldCat Discovery lors de l'utilisation de ces fonctionnalités :
Tri des résultats de recherche :
- Auteur (A à Z)
- Titre (A-Z)
Le filtre de recherche Auteur a été élargi avec Voir plus :
- Le filtre Auteur affiche les auteurs triés par nombre de notices correspondantes (par ordre décroissant). Si l'option Voir plus est sélectionnée, les auteurs sont alors triés par ordre alphabétique.
- Si les résultats élargis et triés alphabétiquement comprend les noms d'auteur en divers jeux de caractères, les noms en caractères latins sont affichés en premier, suivis des noms dans d'autres jeux de caractères.
Survol du rayon depuis l'écran des détails sur le document :
- Survol du rayon en utilisant le tri des cotes. Le tri par cote permet généralement de différencier les documents ayant la même cote à l'aide d'un suffixe alphabétique. Par exemple, QV772 ร451 serait trié avant QV772 ล148ย parce que ร est trié avant ล.
Recherche de données dans les notices de fonds locaux (NFL)
Le tableau suivant répertorie les éléments de données et les zones disponibles pour la recherche dans les notices de fonds locaux (NFL) dans Connexion, FirstSearch, WorldShare et WorldCat Discovery.
Espacement
Pour tous les types de recherches : n'inscrivez pas d'espace entre le libellé d'index et le signe de ponctuation, ou entre le digne de ponctuation et le terme de recherche.Exemple : kw:logiciel
Caractères spéciaux dans les recherches avec les caractères latins
Le tableau suivant indique comment les signes de ponctuation, les signes diacritiques et les caractères spéciaux doivent être employés dans les termes de recherche ou de survol dans WorldCat.
- Caractères spéciaux dans les recherches avec les caractères latins - Tableau
-
Nom Caractère Comment utiliser dans les termes de recherche et de survol æ ou Æ 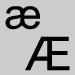
Utiliser les lettres ae. Accent aigu 
Omettre et fermer l'espace. Demi-cercle droit 
Omettre et fermer l'espace. Presque égal à 
Omettre et laisser une espace. Esperluette 
Inscrire. Apostrophe 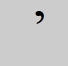
- Omettre et fermer l'espace.
- Omettre dans les recherches de mots. Les mots qui sont précédés d'une seule lettre c, d, j, l, m, n, s ou t et une apostrophe ne sont pas encore normalisés dans le système (ils ne sont pas indexés ensemble afin que les mêmes notices soient repérées pour le terme de recherche, qu'il soit précédé ou non des caractères). Pour l’instant, vous pouvez entrer les deux formes en les combinant avec OU pour trouver toutes les notices pertinentes.
Par exemple, pour chercher l'étranger, inscrivez étranger ou létranger. - Omettre dans les recherches par Indice de classification Dewey. Toutefois, si les indices de classification Dewey contiennent des barres obliques, le système indexe ces indices avec et sans les données qui suivent les barres obliques. Par exemple, 123.45/67/89 est indexé comme 123.45 et 123.4567 et 123.456789
Astérisque 
Omettre et laisser une espace. Arobase 
Omettre et laisser une espace. Aïn 
Omettre et fermer l'espace. Barre oblique inverse 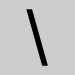
- Omettre et laisser une espace.
- Inscrire lors d'une recherche par Méthode d'accès - expression.
Crochets et informations entre crochets 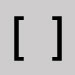
Omettre et fermer l'espace.
- Omettre les crochets ouvrants et fermants et fermer l’espace.
- Omettre les crochets et les données entre les crochets dans ces deux cas :
- [sic]
- [i.e. et les données qui suivent]
- Sinon, inclure les informations entre crochets dans les recherches.
Accent grave 
Omettre et fermer l'espace. Livre sterling 
Omettre et laisser une espace. Candrabindu 
Omettre et fermer l'espace. Cédille 
Omettre et fermer l'espace. Lettre avec rond en chef (angström) 
Omettre et fermer l'espace. Lettre avec rond souscrit 
Omettre et fermer l'espace. Accent circonflexe, sécable ou insécable 
- Omettre et fermer l'espace, sauf dans les URL : inclure l'accent circonflexe sécable.
- Ajouter à certains types de recherches dérivées pour plus de précision.
Deux-points 
Omettre et laisser une espace. Double accent grave 
Omettre et fermer l'espace. Hameçon rétroflexe 
Omettre et fermer l'espace. Brève inférieur inversée 
Omettre et fermer l'espace. Macron inférieur 
Omettre et fermer l'espace. Virgule 
- Omettre et laisser une espace. Certaines exceptions :
- Omettre et fermer l’espace si la virgule est précédée et suivie d’un chiffre.
- Inclure la première virgule dans une recherche de nom par expression ou par expression complète (index qui comprennent les zones 100 $a et 700 $a), si ce n’est pas la dernière virgule dans la sous-zone.
- Utiliser pour séparer les parties d'une recherche dérivée.
Symbole Copyright 
Omettre et fermer l'espace. D barré 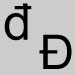
Utiliser la lettre d Accolades 
Omettre et fermer l'espace. Obèle 
Omettre et laisser une espace. Symbole degré 
Omettre et fermer l'espace. Délimiteur 
Omettre, ainsi que la lettre ou le chiffre qui suit, et laisser une espace. Signe division 
Inscrire. Symbole du dollar 
Omettre et laisser une espace. Si utiliser comme délimiteur, omettre également la lettre ou le chiffre qui suit. Lettre avec rond souscrit 
Omettre et fermer l'espace. Double accent aigu 
Omettre et fermer l'espace. Tréma souscrit 
Omettre et fermer l'espace. Double tilde, moitiés gauche et droite 
Omettre et fermer l'espace. Double trait souscrit 
Omettre et fermer l'espace. Flèche vers le bas 
Omettre et laisser une espace. Signe égal 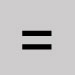
- Omettre et laisser une espace.
- Utiliser pour précéder une recherche dérivée de nom de collectivité, mais uniquement si le libellé d'index n'est pas utilisé.
Eszett (lettre S dur) 
Inscrire l'eszett ou inscrire deux s : ss Eth 
Utiliser la lettre d Euro 
Omettre et laisser une espace. Point d'exclamation 
Omettre et laisser une espace. Indicateur ordinal féminin 
Utiliser la lettre a Accent grave, sécable ou insécable 
Omettre et fermer l'espace, sauf dans les URL : inclure l'accent grave sécable. Supérieur ou égal à 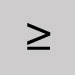
Omettre et laisser une espace. Supérieur à 
Omettre et laisser une espace. Caron (hatchek) 
Omettre et fermer l'espace. Virgule en chef centrée 
Omettre et fermer l'espace. Virgule en chef décentrée 
Omettre et fermer l'espace. O avec crochet en chef 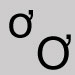
Utiliser la lettre o U avec crochet en chef 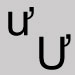
Utiliser la lettre u Trait d’union (signe moins) 
Omettre et laisser une espace. Thorn 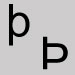
Utiliser les lettres th Infini 
Omettre et laisser une espace. Intégrale 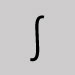
Omettre et laisser une espace. Cédille vers la droite 
Omettre et fermer l'espace. Point d'exclamation renversé 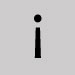
Omettre et fermer l'espace. Point d'interrogation renversé 
Omettre et fermer l'espace. Lettre majuscule latine ENG 
Utiliser la lettre n Lettre majuscule latine ETH 
Utiliser la lettre d Lettre majuscule latine EZH 
Utiliser la lettre z Lettre majuscule latine G avec barre 
Utiliser la lettre g Lettre majuscule latine H avec barre 
Utiliser la lettre h Lettre majuscule latine L avec point au milieu 
Utiliser la lettre l Lettre majuscule latine T avec barre 
Utiliser la lettre t Lettres latines 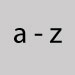
Inscrire les majuscules ou minuscules. Lettre minuscule latine eng 
Utiliser la lettre n Lettre minuscule latine ezh 
Utiliser la lettre z Lettre minuscule latine g avec barre 
Utiliser la lettre g Lettre minuscule latine h avec barre 
Utiliser la lettre h Lettre minuscule latine kra 
Utiliser la lettre q Lettre minuscule latine l avec point au milieu 
Utiliser la lettre l Lettre minuscule latine s long 
Utiliser la lettre s Lettre minuscule latine t avec barre 
Utiliser la lettre t Crochet droit 
Omettre et fermer l'espace. Flèche bilatérale 
Omettre et laisser une espace. Flèche vers la gauche 
Omettre et laisser une espace. Inférieur ou égal à 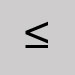
Omettre et laisser une espace. Inférieur à 
Omettre et laisser une espace. Ligature, gauche et droite 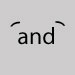
Omettre et fermer l'espace. Macron 
Omettre et fermer l'espace. Indicateur ordinal masculin 
Utiliser la lettre o Lettre modificative prime 
Omettre et fermer l'espace. Symbole micro 
Omettre et laisser une espace. Point central 
Omettre et fermer l'espace. Signe multiplication 
Inscrire. Pas égal à 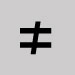
Omettre et laisser une espace. Signe négation 
Omettre et laisser une espace. Dièse 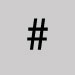
Omettre et laisser une espace. Note. - WorldShare et WorldCat Discovery cherchent automatiquement #TermeDeRecherche comme TermeDeRecherche (ex. : #girlboss est cherché comme girlboss).
Chiffres 
Inscrire. œ ou Œ 
Utiliser les lettres oe Parenthèses 
Omettre et fermer l'espace. Utiliser uniquement pour imbriquer des recherches avec opérateurs booléens. Symbole marque déposée 
Omettre et laisser une espace. Symbole pour cent 
Omettre et laisser une espace. Point (signe décimal) 
- Omettre et fermer l'espace pour les recherches dérivées.
- Omettre et laisser l'espace dans les recherches de mots sauf lorsque des chiffres précèdent ou suivent le point.
- Inscrire le premier point dans une recherche par indice de classification.
Symbole de copyright phonographique 
Omettre et fermer l'espace. Pied-de-mouche (signe de paragraphe) 
Omettre et laisser une espace. Signe plus 
- Omettre dans les recherches de mots.
- Inclure dans les recherches par expression ou par expression complète.
Signe plus-ou-moins 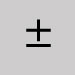
Omettre et laisser une espace. L polonais 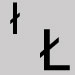
Utiliser la lettre I (ell) Pseudo-point d'interrogation 
Omettre et fermer l'espace. Point d’interrogation 
Omettre et laisser une espace. Guillemet anglais 
- Omettre et laisser une espace.
- Utiliser pour imbriquer plusieurs mots dans une recherche par mots afin de récupérer la séquence exacte de mots.
Crochet droit 
Omettre et fermer l'espace. Flèche vers la droite 
Omettre et laisser une espace. o scandinave 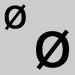
Utiliser la lettre o Minuscule L de ronde 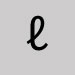
Utiliser la lettre l (ell) Paragraphe 
Omettre et laisser une espace. Point-virgule 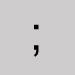
Omettre et laisser une espace. Barre oblique 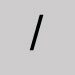
- Utiliser une espace.
- Omettre et fermer l'espace pour les recherches par numéros et les recherches dérivées.
- Inclure comme préfixe aux délimiteurs « barre oblique ».
- Omettre dans les recherches par Indice de classification Dewey. Toutefois, si les indices de classification Dewey contiennent des barres obliques, le système indexe ces indices avec et sans les données qui suivent les barres obliques. Par exemple, 123.45/67/89 est indexé comme 123.45 et 123.4567 et 123.456789.
Espace 
- Fermer les espaces multiples adjacents à une espace.
- Omettre les espaces au début et à la fin.
Racine carrée 
Omettre et laisser une espace. Délimiteur de sous-zone (Voir délimiteur). Signe moins indice inférieur 
Omettre et laisser une espace. Chiffres souscrits 
Utiliser les chiffres 0 à 9. Parenthèses souscrites 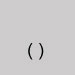
Omettre et fermer l'espace. Signe plus indice inférieur 
Omettre et laisser une espace. Point supérieur 
Omettre et fermer l'espace. Signe moins indice supérieur 
Omettre et laisser une espace. Chiffres indice supérieur (exposant) 
Utiliser les chiffres 0 à 9. Parenthèses exposant 
Omettre et fermer l'espace. Signe plus indice supérieur 
Omettre et laisser une espace. Tilde, sécable ou insécable 
Omettre et fermer l'espace, sauf dans les URL : inclure le tilde d'espacement dans les URL. i turque 
Utiliser la lettre i Tverdyi znak 
Omettre et fermer l'espace. Tréma 
Omettre et fermer l'espace. Souligné, sécable ou insécable 
Omettre et fermer l'espace, sauf dans les URL : inclure le souligné d'espacement dans les URL. Flèche haut et bas 
Omettre et laisser une espace. Upandhmaniya 
Omettre et fermer l'espace. Flèche vers le haut 
Omettre et laisser une espace.
Racine des mots
Note :
- Cette fonctionnalité n'est pas activée pour les collections de requêtes dans Connexion, FirstSearch, ou Gestion des collections WorldShare.
- Cette fonctionnalité fonctionne uniquement avec les recherches par mot-clé.
L'extraction de la racine consiste à étendre la recherche à tous les termes qui ont la même racine que le mot figurant dans l'énoncé de recherche afin que toutes les notices contenant une forme du mot soient incluses dans l'ensemble de résultats. Par exemple, une recherche pour victim sera traitée comme suit : victime OU victimologie OU victimisation.
Exemple en anglais utilisé ci-dessous : acceleration OR accelerations OR accelerating.
| Chercher dans WorldCat Discovery | Type de recherche | Extraction de la racine du mot | Équivaut à chercher |
|---|---|---|---|
| acceleration | mot-clé | Oui | acceleration OR accelerations OR accelerating |
| kw:acceleration | mot-clé | Oui | acceleration OR accelerations OR accelerating |
| "acceleration" | expression exacte | Non | acceleration |
| kw: "acceleration" | expression exacte | Non | acceleration |
Mots vides
Les mots vides (mots ignorés) sont des mots communs que le système ignore lors de certains types de recherches. Vous pouvez les omettre dans votre énoncé de recherche. Pour utiliser l'un de ces mots comme terme de recherche, mettez-le entre guillemets droits ("mot").
Mots vides dans WorldShare et WorldCat Discovery
Les listes de mots vides dans WorldShare et WorldCat Discovery s'appliquent aux index suivants :
Mots vides dans Connexion, FirstSearch et les collections de requêtes dans Gestion des collections WorldShare.
Les listes de mots vides dans Connexion, FirstSearch et les collections de requêtes dans Gestion des collections WorldShare s'appliquent aux index ci-dessous.